
Ethical AI Development for Writers: Data, Bias, and Transparency
Build ethical AI writing tools: source data with consent, identify bias in datasets, and maintain transparency. Complete guide for writers fine-tuning LLMs.


When Legal Isn’t Enough: Ethical AI Training Data
You’ve done your homework. Your AI training dataset is squeaky clean—public domain texts, properly licensed Creative Commons works, maybe some content you wrote yourself. You’ve read the copyright guides, consulted the legal frameworks, and documented everything meticulously.
Congratulations. You’ve cleared the legal bar.
But here’s the uncomfortable truth: just because you can legally use certain training data doesn’t mean you should. Copyright law establishes the minimum standard.
Ethical AI development asks harder questions: What kind of AI developer do you want to be? How do you build AI writing tools that respect the creative community?
If you’re just starting to understand legal compliance, see:

Embracing AI As A Creative Ally
You’ve done your homework. Your training dataset is squeaky clean—public domain texts, properly licensed Creative Commons works, and, hopefully, some content you wrote yourself. You’ve read the copyright guides, consulted the legal frameworks, and documented everything.
But here’s the real question: now that legality is settled, how do we shape the ethics of creativity in the age of AI?
Imagine AI not as a threat to originality, but as a springboard for possibility. When used thoughtfully, AI can help writers rediscover their creative spark, offering new ways to express their voices. Ethical considerations aren’t about restraining creativity—they’re about guiding it with curiosity, respect, and transparency.
In this article, we’ll explore how ethical practices with AI empower writers, illustrated by real-world examples and practical advice. Let’s start with the foundation: where our data comes from and why it matters.
Sourcing Ethical AI Training Data: Consent and Documentation
The Consent Problem Nobody Talks About
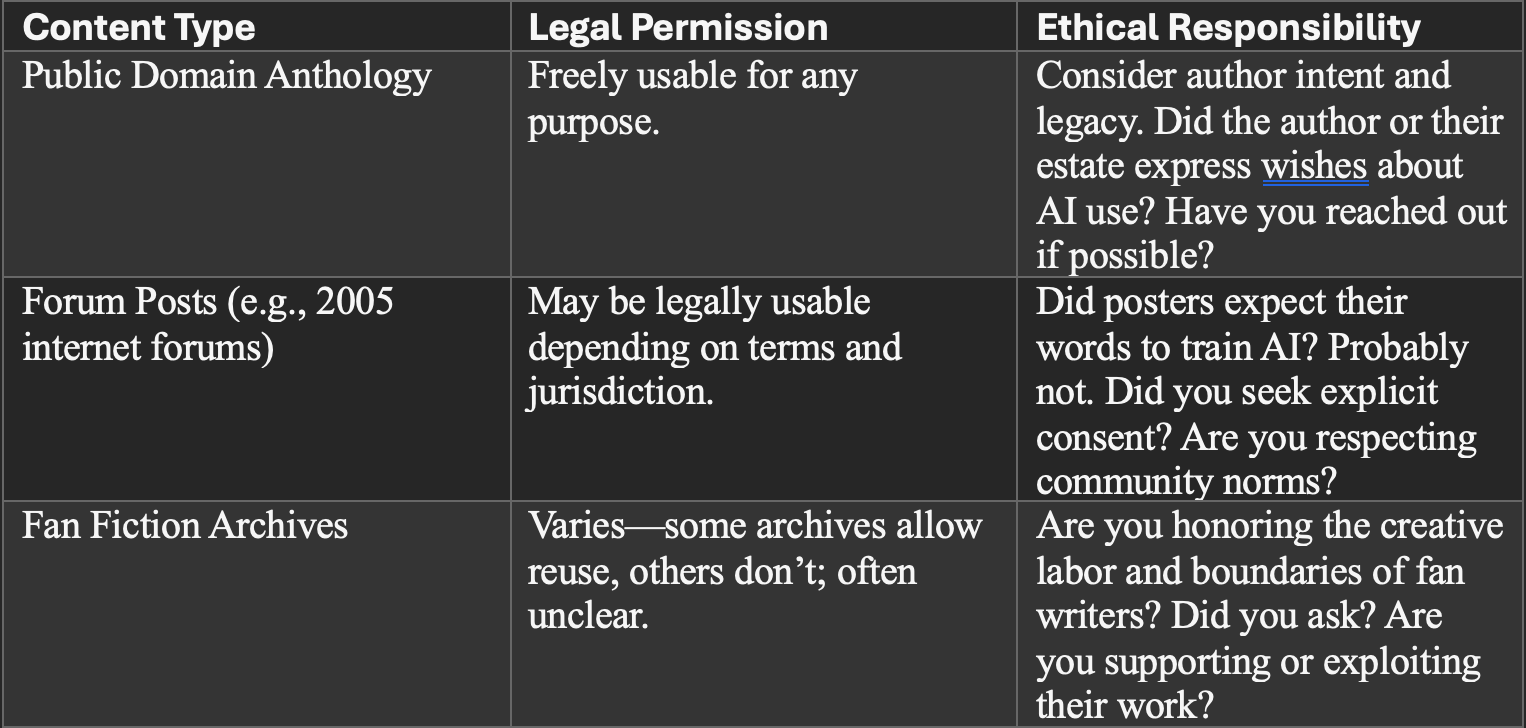
Here’s a scenario: You find a science fiction anthology on Project Gutenberg. It’s from 1922, solidly public domain. Legal gold mine, right?
But here’s what the copyright checklist doesn’t tell you: that anthology contains a story by a writer whose descendants are still alive and actively managing his literary estate. They’ve publicly stated they oppose AI training on his work. Legally, you’re fine. Ethically? You’re in murky water.
For more on public domain sourcing, see:

Consent documentation isn’t just about avoiding lawsuits. It’s about treating other writers’ labor with respect. “Explicit written permission,” means actual communication with living creators, not just checking a CC license checkbox.
This gets complicated fast. What about forum posts from 2005? Reddit threads? Fan fiction archives? Technically, some of these might be legal to use. But did those writers post their work thinking it might train commercial AI systems? Unlikely.
Writers deserve more than checkbox consent. They deserve respect.
Legal Permission vs. Ethical Responsibility: A Quick Guide
Case Study: Listening to Marginalized Authors
In 2023, Meta’s LLaMA model was trained on a dataset including pirated book scraped from “shadow libraries”. The authors affected included Melissa Lucashenko, a Goorie writer of Bundalung and European background. Lucashenko’s writing is rooted in Indigenous storytelling tradition and lived experienced.
Despite their works being publicly available, these writers did not consent to their work trained on AI and expressed outrage at the ethical disregard for their creative labor.
In late 2024, a survey of 400 members of the Australian Society of Authors revealed that 79% of Australian authors would not allow existing work to be used to train AI models, even if paid. Seventy-seven percent said the same about future work.
In 2023, Meta’s LLaMA model was trained on a dataset including pirated book scraped from “shadow libraries”. The authors affected included Melissa Lucashenko, a Goorie writer of Bundalung and European background. Lucashenko’s writing is rooted in Indigenous storytelling tradition and lived experienced.
Despite their works being publicly available, these writers did not consent to their work trained on AI and expressed outrage at the ethical disregard for their creative labor.
In late 2024, a survey of 400 members of the Australian Society of Authors revealed that 79% of Australian authors would not allow existing work to be used to train AI models, even if paid. Seventy-seven percent said the same about future work.
“For many authors, their work is more than just intellectual property. It represents their voice, their identity and years of creative labour, often undertaken with little financial return.”
Why This Matters
Marginalized authors share their culture, memories, and personal history. Their stories come from real experiences and backgrounds often overlooked or excluded.
When AI companies use these stories as training data without consent, authors lose what makes these works unique. Ignoring the boundaries set by writers strips away the meaning and depth of their stories, turning them into plain data.
Their writing is used for its language, but their names, earnings, and intentions are ignored. This problem affects many communities, from Black authors in the U.S. to Indigenous writers in Australia.
Ethical Data Sourcing in Practice: A Case Study
Let me tell you about Elena, a fantasy writer who wanted to train a model on high fantasy conventions without scraping the internet. She spent three months building a dataset from:
Pre-1928 fantasy and adventure stories (public domain)
Her own 200,000 words of unpublished fantasy writing
Work from five writer friends who explicitly agreed and wanted to see the results
Creative Commons fantasy stories where she contacted each author individually
The process was slower than scraping would have been. But the result was a model with a distinctive voice that reflected intentional choices about what fantasy tropes to emphasize. More importantly, when she shared her process in her writing community, other writers asked to contribute their work because they trusted her approach.
That’s what ethical data sourcing creates: trust, collaboration, and tools that feel like they belong to the writing community rather than extraction from it.
Competitive Harm: The Impact of AI-Generated Genre Fiction
Imagine this: you train your AI on cozy mystery stories using texts you found legally online. Sounds harmless, right?
But then your AI starts churning out new cozy mysteries and you put them up for sale on Amazon. Now, you’re not just having fun—you’re competing against the human writers who created the very stories your AI learned from.
This isn’t just a far-fetched worry; it’s happening right now.
For instance, the romance section on Amazon is flooded with AI-generated books mimicing the structure and style of human romance authors. Those writers are seeing their sales drop because they’re suddenly up against computer-generated books built from their own creative work.
But here’s the distinction that matters: There’s a difference between training AI on romance conventions to help you write your own romance novel, and training it to mass-produce romance novels for passive income. The first uses AI to develop your voice. The second uses AI to flood the market with content that undercuts human writers—including you, eventually.
The ethical question: How do you use AI to support your own writing practice without contributing to a system that devalues writing as labor?
For a comprehensive guide to legal data, see:

Identifying and Addressing Bias in AI Training Datasets

Dataset Diversity: Why Classic Literature Isn’t Enough
You might think: “I’ll avoid contemporary controversies by training exclusively on classic literature. Problem solved!”
Not quite. Classic literature is the problem—or at least, exclusively training on it is.
How AI Amplifies Bias in Training Data
Here’s something unsettling: AI doesn’t just reproduce biases in training data. It often amplifies them.
If your training dataset has ten stories where Black characters are criminals and two where they’re complex protagonists, your AI won’t give you a neutral 12-story average. It learns that the pattern “Black character → criminal” appears more frequently and reproduces it more strongly.
Victorian novels often show women mostly as wives, mothers, or romantic interests—rarely as independent thinkers or leaders. Early adventure tales, like those by Rudyard Kipling or H. Rider Haggard, sometimes portray non-European cultures through a colonial lens, describing them as exotic, primitive, or even inferior.
This means you need to actively audit your training data for harmful patterns:
Romance: Are all healthy relationships heterosexual? Are consent dynamics clear, or is “overcoming resistance” romanticized?
Crime fiction: Do descriptions of criminals correlate with racist stereotypes? Is violence disproportionately directed at women?
Fantasy: Are non-European-coded cultures portrayed as exotic, primitive, or mystical? Is magic racialized?
Horror: Are mental illness and disability used as shorthand for danger? Is the “dangerous madman” your go-to villain?
You don’t need to achieve perfect representation. But you need to notice the patterns and make conscious choices about them.
Transparency in AI Development: Documentation and Disclosure
AI Writing Disclosure: When and How to Be Transparent
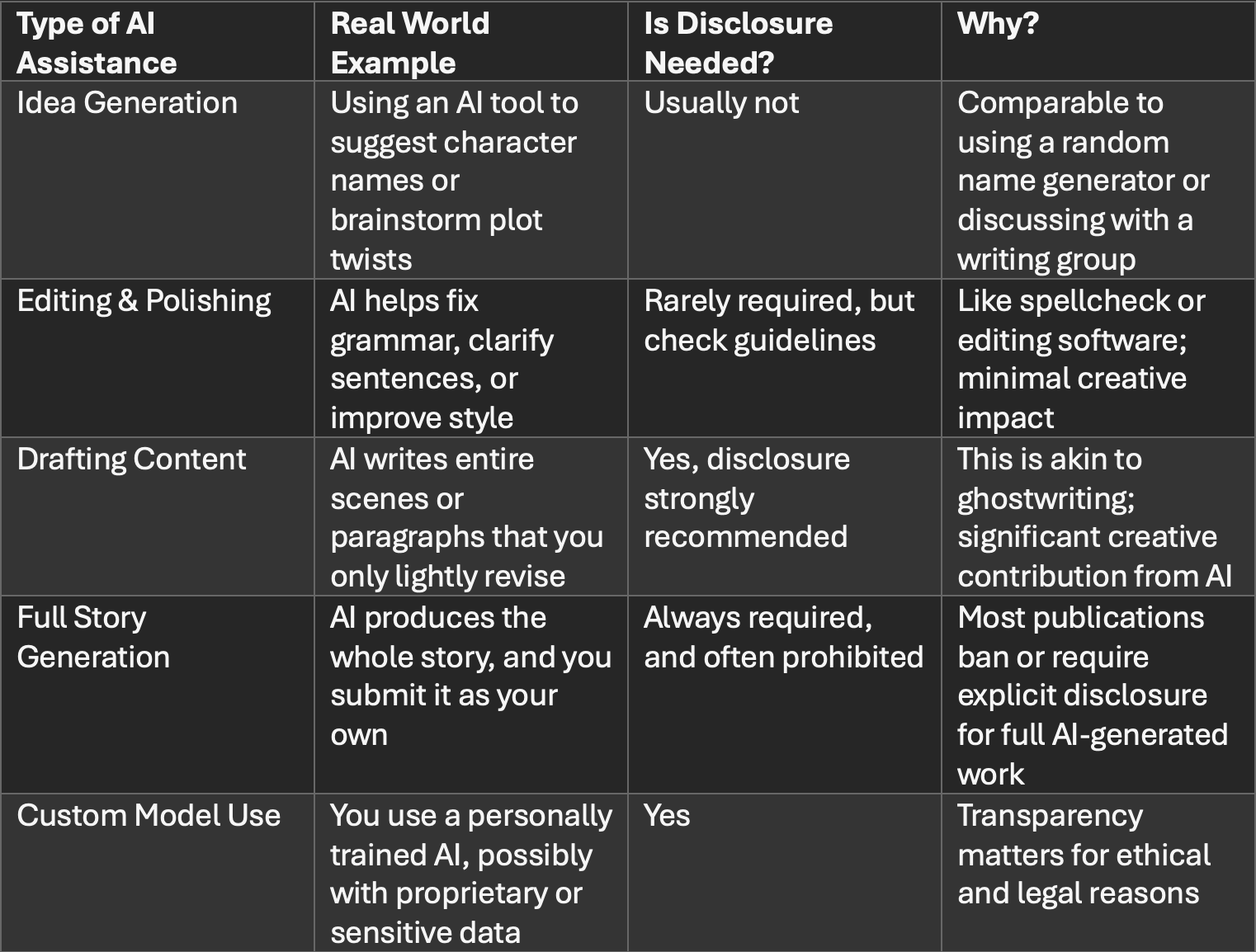
Do you need to disclosure you novel was written with AI assistance? Honestly, it depends on how you define “assistance” and where you’re submitting or publishing.
If AI helped you brainstorm plot points, that would probably be like talking through ideas with a writing group. If AI generated full paragraphs that you lightly edited, that’s ghostwriting. If you used AI to polish your prose, that’s somewhere in between.
You might have a lot of questions about when it’s appropriate to disclose AI use. I’ve put together a table featuring common scenarios.
Why Disclosure Matters
This isn’t about judging if AI is right or wrong. It’s about maintaining trust with your readers, editors, and other writers.
Not being upfront about your AI use can have serious consequences. If editors or readers discover that your work is more AI-written than you claimed, it can damage your credibility and erode trust.
A common complaint about AI use in the writing community is lack of transparency. A simple rule to go by: If you wouldn’t feel comfortable describing exactly how you used AI, it’s probably a sign that you should.
Frequently Asked Questions
What is the difference between legal and ethical AI training data?
Legal data meets the minimum standards of copyright law, while ethical data considers consent, cultural context, and the impact on creators. Just because something is legal doesn’t mean it’s right to use.
Read more about Copyright and AI.
Can I use Creative Commons content to train AI?
Yes, but only if the license allows for commercial use and derivative works. Even then, it’s best to contact the creator directly for informed consent.
Check out the Creative Commons license types for clarity.
How do I audit my dataset for bias?
Start by categorizing your data by genre, theme, and representation. Look for patterns that reinforce stereotypes or exclude marginalized voices. Use tools like Perspective API or collaborate with sensitivity readers.
Should I disclose AI use in my writing?
Yes, especially if AI generated significant portions of the text. Transparency builds trust with readers and editors. If you’re unsure, err on the side of disclosure.
Read more about AI disclosure in publishing.
How can I ethically source data for AI training?
Use public domain works from before 1928
Write your own content
Get written permission from living authors
Use Creative Commons works with proper licenses
Avoid scraping forums, fan fiction, or shadow libraries
Building Your Ethical Foundation
Getting your data sourcing right, understanding bias in your training set, and committing to transparency—these aren’t obstacles to building AI writing tools. They’re the foundation that makes those tools worth building.
When you take the time to:
Source data with genuine consent and respect for other writers’ labor
Actively audit for bias rather than assuming neutrality
Document your choices and communicate them honestly
You’re not just protecting yourself legally. You’re creating tools that the writing community can actually trust.
But ethical AI development doesn’t end when training finishes. Once your model is running, a new set of questions emerges: How do you use it responsibly? What creative decisions remain yours? How do you monitor for problems that emerge over time?
Those questions—about workflows, creative practice, and ongoing responsibility—require just as much intentionality as data sourcing did.
This series:
Part 1: Why Your AI Writes Like A Robot (And How To Fix It)
Part 2: Why Your AI Data Training Set Is Illegal (And How To Fix It)
✓ Ethical AI Development: Foundations (Data, Bias, Transparency) ← You are here
Next: Ethical AI Development: Practice (Workflows and Responsibility)